|
I am a research fellow at Microsoft Research India, where I am advised by Navin Goyal. Before joining MSR, I did research internships with David Krueger and Puneet Dokania at Cambridge University and Five AI Oxford, where my work focussed on developing a better understanding of (safety) fine-tuning using mechanistic interpretability. Even before this, I completed my Bachelors and Masters in CSE at Indian Institute of Technology (BHU) Varanasi and during this time, I worked with Venkatesh Babu and Sravanti Addepalli at Indian Institute of Science, Bangalore. Here, my research focussed on developing adversarially robust defences. I am very interested in developing a better understanding of learning dynamics of neural networks, which can help us explain different intriguing observations: phase transitions, neural collapse, simplicity bias, etc. For this I aim to combine tools from learning theory and mechanistic interpretability. I believe in using toy setups to develop hypotheses explaining real world observations and later test these hypotheses at scale. I am always motivated to deliver impactful work enhancing our scientific understanding while being useful in practice. I am also interested in domains related to AI Safety, like cooperative alignment, adversarial robustness, reward hacking and safety fine-tuning. Email / CV / Google Scholar / Github / Twitter |

|
|
|
|

|
Samyak Jain, Ekdeep Singh Lubana, Kemal Oksuz, Tom Joy, Philip H.S. Torr, Amartya Sanyal, and Puneet K. Dokania Advances in Neural Information Processing Systems (NeurIPS), 2024 ICML workshop on Mechanistic Interpretability , 2024 (Spotlight) bibtex / arXiv We use fomral languages as a model system to identify the mechanistic changes induced by safety fine-tuning, and how jailbreaks bypass these mechanisms, verifying our claims on Llama models. |
|
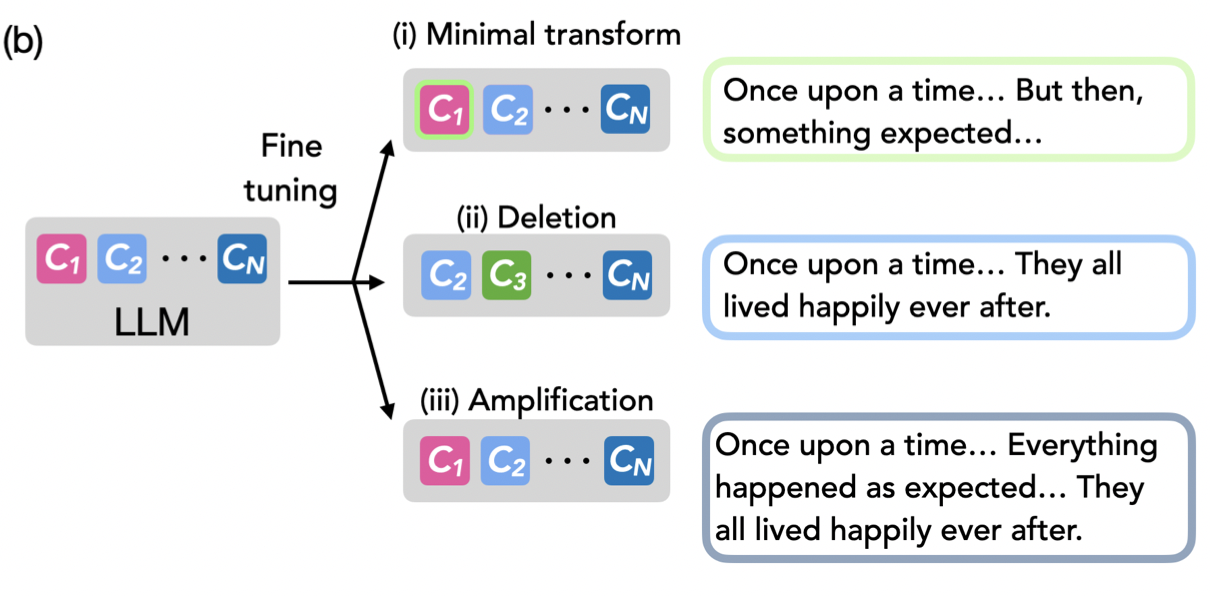
Samyak Jain*, Robert Kirk*, Ekdeep Singh* Robert P. Dick, Hidenori Tanaka, Edward Grefenstette, Tim Rocktaschel, and David Krueger International Conference on Learning Representations (ICLR), 2024 bibtex / arXiv We show fine-tuning leads to learning of minimal transformations of a pretrained model's capabilities, like a "wrapper", by using procedural tasks defined using Tracr, PCFGs, and TinyStories. |
|
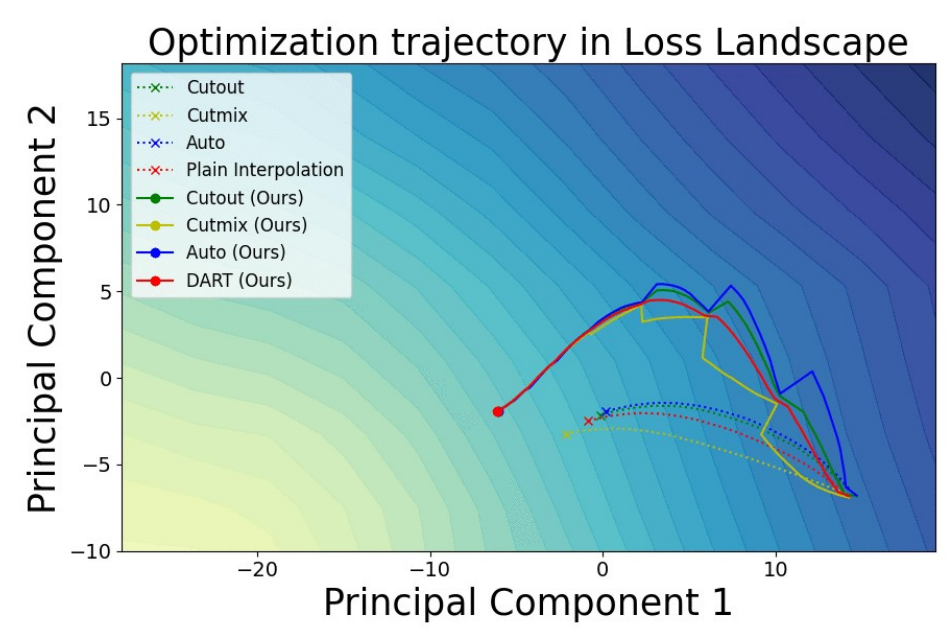
Samyak Jain*, Sravanti Addepalli*, Pawan Kumar Sahu, Priyam Dey, and R. Venkatesh Babu Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023 bibtex / arXiv We demonstrate state of the art domain generalization performance on domainbed by effectively traversing the loss landscape using multiple copies of a model and later merging them to converge onto a flatter minima |
|
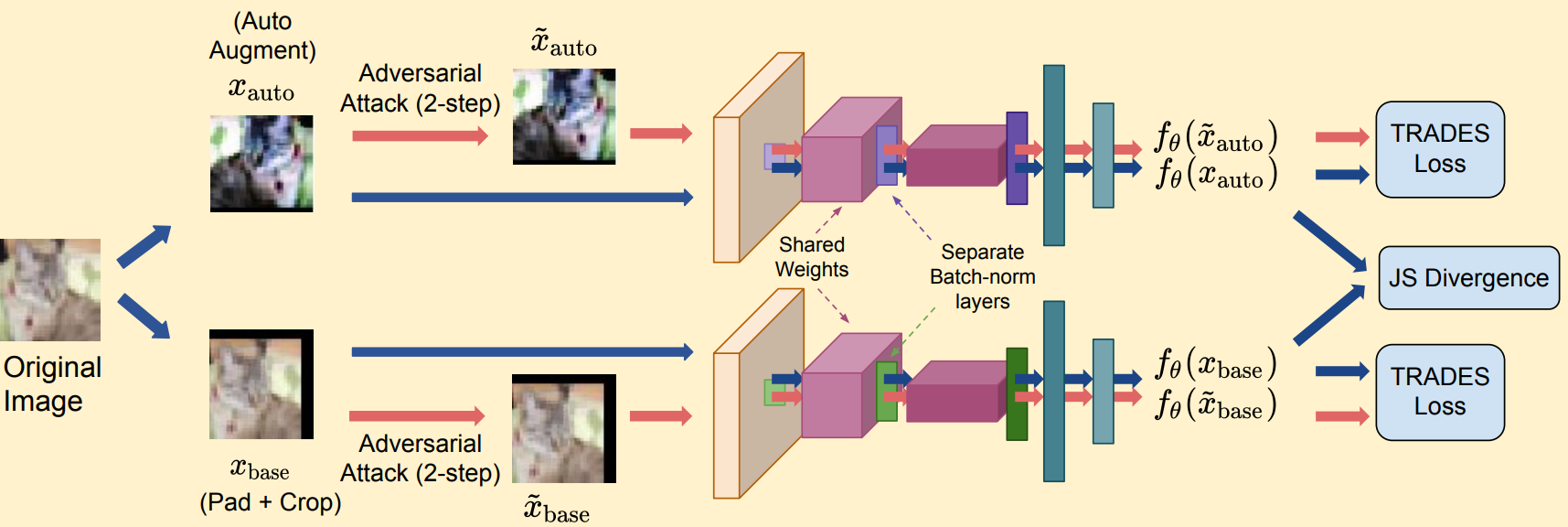
Sravanti Addepalli*, Samyak Jain*, and R. Venkatesh Babu Advances in Neural Information Processing Systems (NeurIPS), 2022 bibtex / arXiv Propose to counter the distribution shift caused on using augmentations in adversarial training via multiple batch normalization layers specialized for weak and strong augmentations. |
|
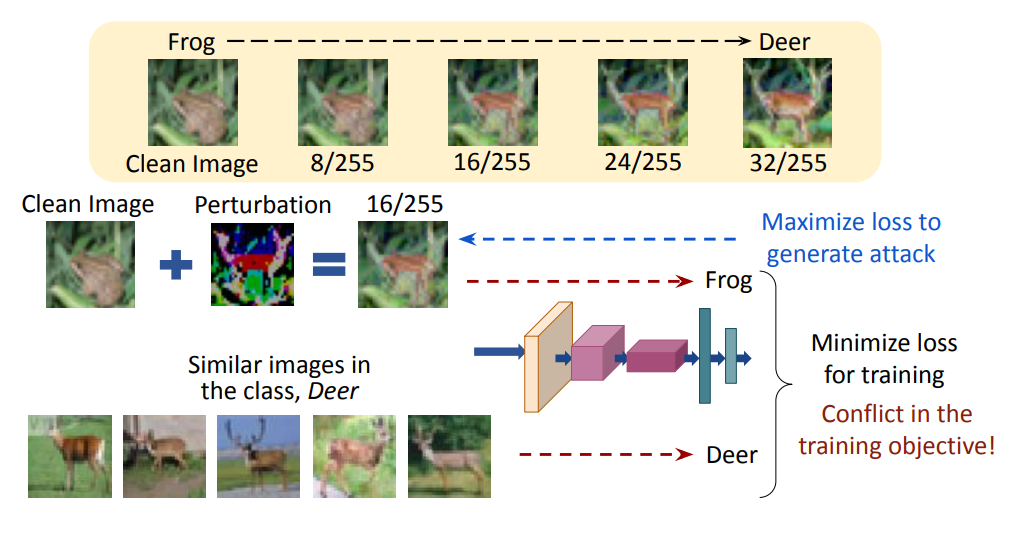
Sravanti Addepalli*, Samyak Jain*, Gaurang Sriramanan and R. Venkatesh Babu European Conference on Computer Vision (ECCV), 2022 bibtex / arXiv Demonstrated that standard adversarial training method cannot generalize to larger perturbation bounds due to flipping of the oracle labels of some images. We propose oracle aligned adversarial training to overcome this issue. |
|
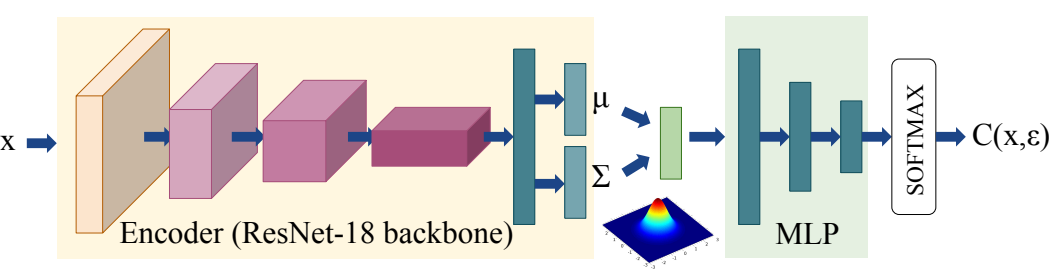
Sravanti Addepalli*, Samyak Jain*, Gaurang Sriramanan* and R. Venkatesh Babu Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPR Workshops), 2022 bibtex / arXiv Proposed a stochastic classifier, which aims to learn smoother class boundaries by sampling noise multiple times in its latent space during inference. This results in improved robustness along with better calibration. |
|
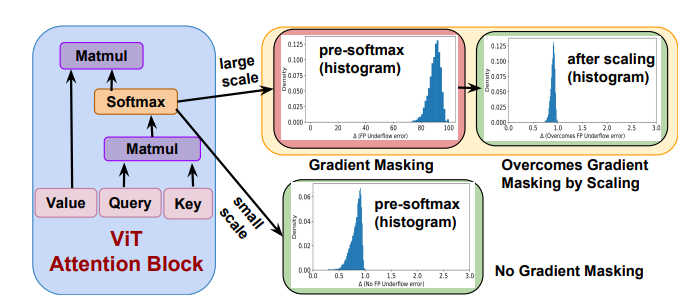
Samyak Jain, and Tanima Dutta Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024 bibtex / arXiv Demonstrated that softmax in self-attention of vision transformers causes floating point errors which leads to gradient masking, thereby highlighting the requirement of adaptive attacks to analyze true robustness. |